基于keras的seq2seq中英文翻译实现 |
您所在的位置:网站首页 › in sequence翻译中文 › 基于keras的seq2seq中英文翻译实现 |
基于keras的seq2seq中英文翻译实现
|
1. seq2seq概述
1.1 seq2seq简介1.2 seq2seq结构 2. 中英文翻译实战
2.1 数据处理2.2 encoder-decoder模型搭建
2.2.1 用于训练的模型2.2.2 用于推理的模型 2.3 模型评价 3 致谢
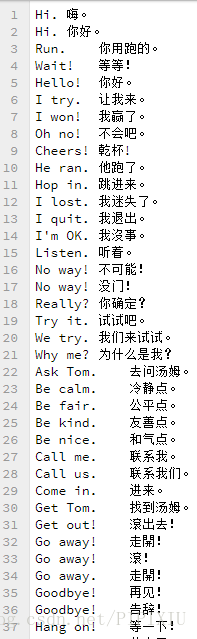
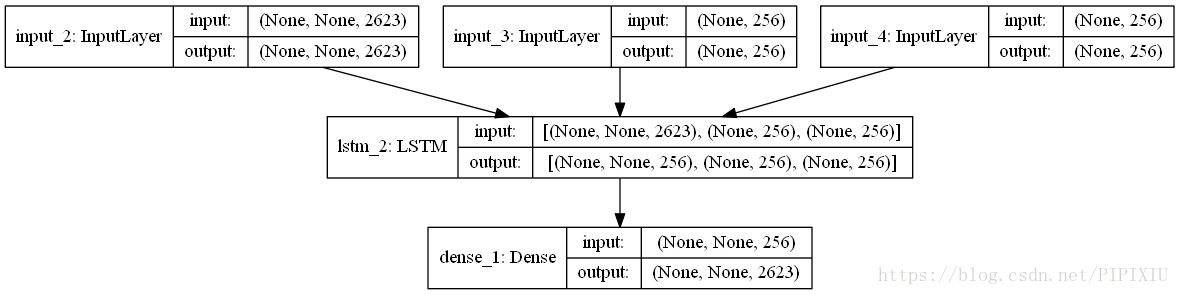
本文详细代码见https://github.com/pjgao/seq2seq_keras/blob/master/seq2seq_keras.ipynb 1. seq2seq概述 1.1 seq2seq简介seq2seq,全称Sequence to sequence,是RNN结构的一个变形,来自于Cho 在 2014 年提出的 Encoder–Decoder 结构,https://arxiv.org/pdf/1406.1078.pdf。 传统的RNN输入和输出长度要一致,而seq2seq在RNN的基础上进行改进,实现了变长序列的输入和输出,广泛的应用在了机器翻译、对话系统、文本摘要等领域。 【seq2seq同时可作为一种特征提取器来提取特征,可参考论文A method for estimating process maliciousness with Seq2Seq model】 seq2seq与Encoder-Decoder: Encoder-decoder是模拟人类认知的一个过程, encoder记忆和理解信息,并提炼信息通常会形成一个低维向量,decoder回忆与运用这些信息,再将加工后的信息输出来。 Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN,RNN,Bi-RNN、LSTM、GRU等等。当encoder和decoder处理的都是序列时称为seq2seq。 1.2 seq2seq结构seq2seq由encoder和decoder组成。 encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。 decoder则负责根据语义向量生成指定的序列,这个过程也称为解码。如下图,这是一种简单的seq2seq,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。 本文使用中英文翻译数据集,来实现字符级的seq2seq模型的训练。 该文件来自于http://www.manythings.org/anki/,包含了20133条中英文翻译。 首先要将数据处理成Keras中模型接受的三维向量。这里需要处理3个向量,分别是encoder的输入encoder_input,decoder的输入和输出decoder_input, decoder_output #读取cmn-eng.txt文件 data_path = 'data/cmn.txt' df = pd.read_table(data_path,header=None).iloc[:NUM_SAMPLES,:,] df.columns=['inputs','targets'] #讲每句中文句首加上'\t'作为起始标志,句末加上'\n'作为终止标志 df['targets'] = df['targets'].apply(lambda x: '\t'+x+'\n') input_texts = df.inputs.values.tolist()#英文句子列表 target_texts = df.targets.values.tolist()#中文句子列表 #确定中英文各自包含的字符。df.unique()直接取sum可将unique数组中的各个句子拼接成一个长句子 input_characters = sorted(list(set(df.inputs.unique().sum()))) target_characters = sorted(list(set(df.targets.unique().sum())))每条句子经过对字母转换成one-hot编码后,生成了LSTM需要的三维输入[n_samples, timestamp, one-hot feature] #encoder输入、decoder输入输出初始化为三维向量 encoder_input = np.zeros((NUM_SAMPLES,INUPT_LENGTH,INPUT_FEATURE_LENGTH)) decoder_input = np.zeros((NUM_SAMPLES,OUTPUT_LENGTH,OUTPUT_FEATURE_LENGTH)) decoder_output = np.zeros((NUM_SAMPLES,OUTPUT_LENGTH,OUTPUT_FEATURE_LENGTH))其中: NUM_SAMPLES,样本条数,这里是输入的句子条数INPUT_LENGTH,输入数据的时刻t的长度,这里为最长的英文句子长度OUTPUT_LENGTH,输出数据的时刻t的长度,这里为最长的中文句子长度INPUT_FEATURE_LENGTH,每个时刻进入encoder的lstm单元的数据 xt x t 的维度,这里为英文中出现的字符数OUTPUT_FEATURE_LENGTH,每个时刻进入decoder的lstm单元的数据 xt x t 的维度,这里为中文中出现的字符数对句子进行字符级one-hot编码,将输入输出数据向量化: #encoder的输入向量one-hot for seq_index,seq in enumerate(input_texts): for char_index, char in enumerate(seq): encoder_input[seq_index,char_index,input_dict[char]] = 1 #decoder的输入输出向量one-hot,训练模型时decoder的输入要比输出晚一个时间步,这样才能对输出监督 for seq_index,seq in enumerate(target_texts): for char_index,char in enumerate(seq): decoder_input[seq_index,char_index,target_dict[char]] = 1.0 if char_index > 0: decoder_output[seq_index,char_index-1,target_dict[char]] = 1.0这里,查看获得的三个向量如下: In[0]: ''.join([input_dict_reverse[np.argmax(i)] for i in encoder_input[0] if max(i) !=0]) Out[0]: 'Hi.' In[1]: ''.join([input_dict_reverse[np.argmax(i)] for i in decoder_output[0] if max(i) !=0]) Out[1]: '嗨。\n' In[2]: ''.join([input_dict_reverse[np.argmax(i)] for i in decoder_input[0] if max(i) !=0]) Out[2]: '\t嗨。\n'其中input_dict和target_dict为中英文字符与其索引的对应词典;input_dict_reverse和target_dict_reverse与之相反,索引为键字符为值: input_dict = {char:index for index,char in enumerate(input_characters)} input_dict_reverse = {index:char for index,char in enumerate(input_characters)} target_dict = {char:index for index,char in enumerate(target_characters)} target_dict_reverse = {index:char for index,char in enumerate(target_characters)} 2.2 encoder-decoder模型搭建我们预测过程分为训练阶段和推理阶段,模型也分为训练模型和推断模型,这两个模型encoder之间deocder之间权重共享。 为什么要这么划分的?我们仔细考虑训练过程,会发现训练阶段和预测阶段的差异。 在训练阶段,encoder的输入为time series数据,输出为最终的隐状态,decoder的输出应该是target序列。为了有监督的训练,decoder输入应该是比输入晚一个时间步,这样在预测时才能准确的将下一个时刻的数据预测出来。 在训练阶段,每一时刻decoder的输入包含了上一时刻单元的状态
ht−1
h
t
−
1
和
ct−1
c
t
−
1
,输出则包含了本时刻的状态
h
h
和cc以及经过全连接层之后的输出数据。 训练时的流程: 训练模型: 其中英文字符(含数字和符号)共有73个,中文中字符(含数字和符号)共有2623个。 encoder推断模型 decoder推断模型 把模型创建整理成一个函数: def create_model(n_input,n_output,n_units): #训练阶段 encoder_input = Input(shape = (None, n_input)) encoder = LSTM(n_units, return_state=True) _,encoder_h,encoder_c = encoder(encoder_input) encoder_state = [encoder_h,encoder_c] #decoder decoder_input = Input(shape = (None, n_output)) decoder = LSTM(n_units,return_sequences=True, return_state=True) decoder_output, _, _ = decoder(decoder_input,initial_state=encoder_state) decoder_dense = Dense(n_output,activation='softmax') decoder_output = decoder_dense(decoder_output) #生成的训练模型 model = Model([encoder_input,decoder_input],decoder_output) #推理阶段,用于预测过程 encoder_infer = Model(encoder_input,encoder_state) decoder_state_input_h = Input(shape=(n_units,)) decoder_state_input_c = Input(shape=(n_units,)) decoder_state_input = [decoder_state_input_h, decoder_state_input_c]#上个时刻的状态h,c decoder_infer_output, decoder_infer_state_h, decoder_infer_state_c = decoder(decoder_input,initial_state=decoder_state_input) decoder_infer_state = [decoder_infer_state_h, decoder_infer_state_c]#当前时刻得到的状态 decoder_infer_output = decoder_dense(decoder_infer_output)#当前时刻的输出 decoder_infer = Model([decoder_input]+decoder_state_input,[decoder_infer_output]+decoder_infer_state) return model, encoder_infer, decoder_infer 2.3 模型评价 def predict_chinese(source,encoder_inference, decoder_inference, n_steps, features): #先通过推理encoder获得预测输入序列的隐状态 state = encoder_inference.predict(source) #第一个字符'\t',为起始标志 predict_seq = np.zeros((1,1,features)) predict_seq[0,0,target_dict['\t']] = 1 output = '' #开始对encoder获得的隐状态进行推理 #每次循环用上次预测的字符作为输入来预测下一次的字符,直到预测出了终止符 for i in range(n_steps):#n_steps为句子最大长度 #给decoder输入上一个时刻的h,c隐状态,以及上一次的预测字符predict_seq yhat,h,c = decoder_inference.predict([predict_seq]+state) #注意,这里的yhat为Dense之后输出的结果,因此与h不同 char_index = np.argmax(yhat[0,-1,:]) char = target_dict_reverse[char_index] output += char state = [h,c]#本次状态做为下一次的初始状态继续传递 predict_seq = np.zeros((1,1,features)) predict_seq[0,0,char_index] = 1 if char == '\n':#预测到了终止符则停下来 break return output对100个值进行预测: for i in range(1000,1210): test = encoder_input[i:i+1,:,:]#i:i+1保持数组是三维 out = predict_chinese(test,encoder_infer,decoder_infer,OUTPUT_LENGTH,OUTPUT_FEATURE_LENGTH) print(input_texts[i]) print(out)我们发现预测的都很准(废话,训练集能不准嘛!) 翻译结果: 本文参照了以下文章: [1] keras/examples/lstm_seq2seq.py, https://github.com/keras-team/keras/blob/master/examples/lstm_seq2seq.py [2] A ten-minute introduction to sequence-to-sequence learning in Keras, https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html [3] How to Develop an Encoder-Decoder Model for Sequence-to-Sequence Prediction in Keras, https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/ [4] Keras-9 实现Seq2Seq, https://blog.csdn.net/weiwei9363/article/details/79464789 [5] 理解LSTM在keras API中参数return_sequences和return_state, https://blog.csdn.net/u011327333/article/details/78501054 [6] Keras关于LSTM的units参数,还是不理解? https://blog.csdn.net/xiewenbo/article/details/79452843 |
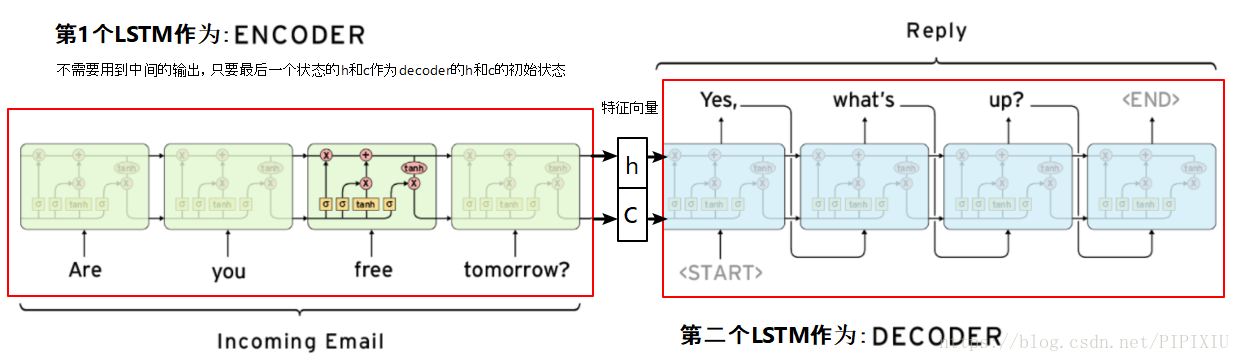
 预测时的流程:
预测时的流程: 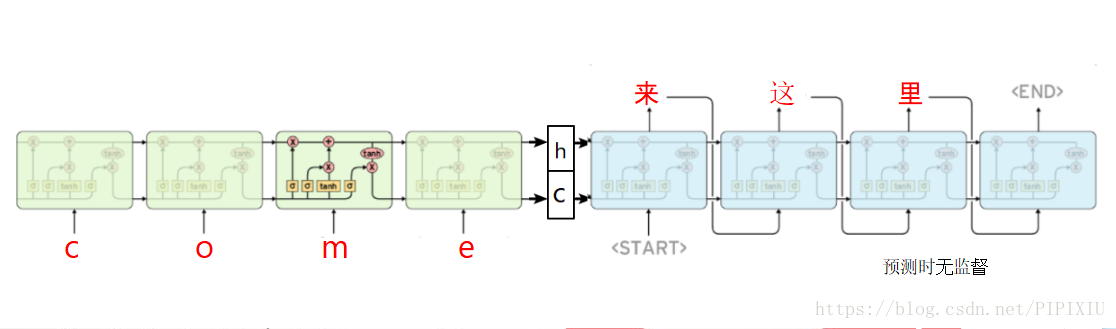
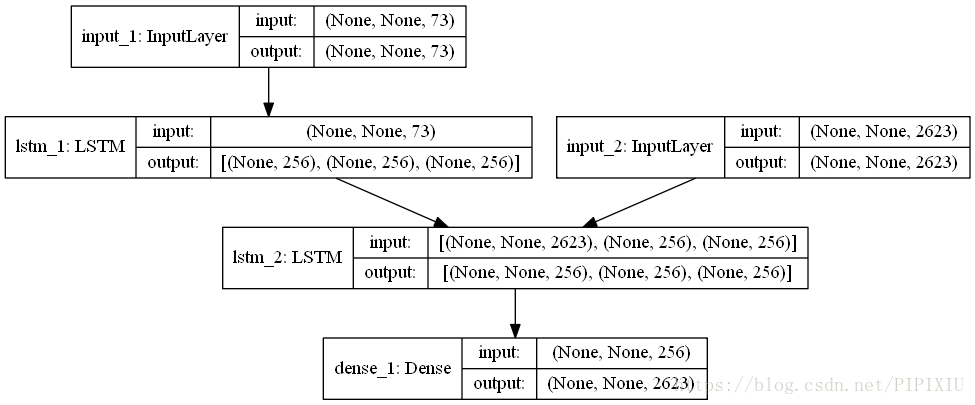


【本文地址】
今日新闻 |
推荐新闻 |